今天來討論機器學習經典的模型之一,CNN又稱捲積神經網路,近年來這個技術大量用於影像辨識和聲音辨識上都有很準確的效果,因為CNN有別於之前的DNN可以使用Convolutional layer來看圖片,對於影像的辨識的參數量也更加勝於DNN。而CNN經典的架構有像是: Le-Net, VGG, GoogleNet, ResNet, DenseNet 等等。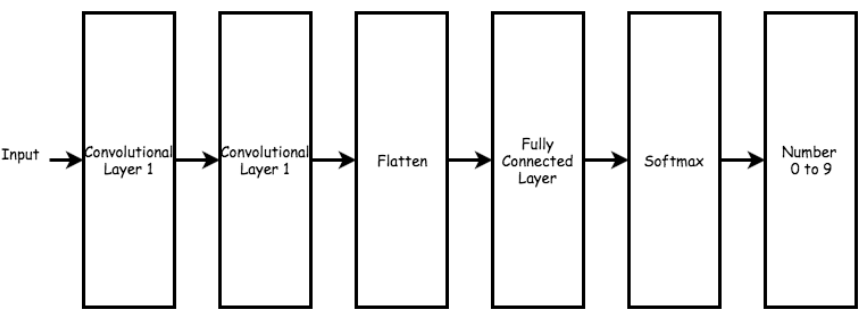
圖片輸入會經過兩個卷積層 (convolutional layer) 然後把它扳平 (Flatten) 之後進入全連結層 (Fully Connected Layer) 最後就是進入 Softmax 分類成 10 個數字.
Filter: 濾波器數目,就是下圖的每一階段的輸出面數或是深度,輸出的圖稱為『特徵圖』(Feature Map),通常是4的倍數。
kernel_size: 卷積核大小,一般為正方形,邊長為奇數,便於尋找中心點
**strides:**滑動步長,計算滑動視窗時移動的格數。
**padding:**補零方式,卷積層取週邊kernel_size的滑動視窗時,若超越邊界時,是否要放棄這個output點(valid)、一律補零(same)
**activation:**要使用何種 activation function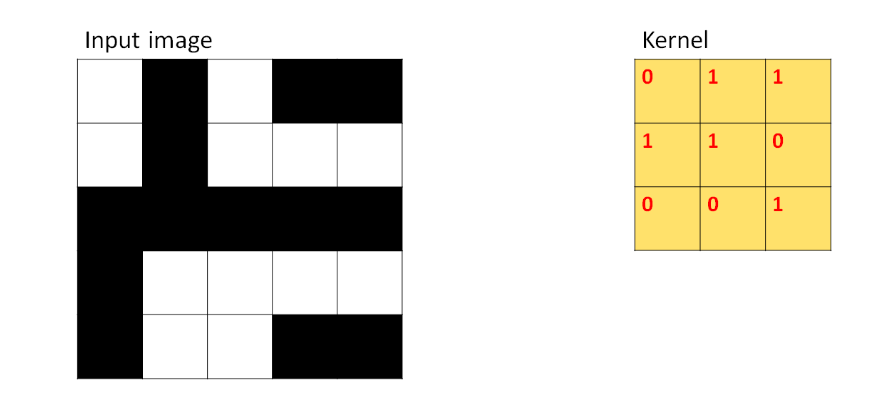
在這卷積的過程中,如果5X5的黑白圖片中有一個形狀與該kernel所表示的形狀類似(即kernel中大於0的格子),就會產生激勵效果,兩者相乘的乘積會變成更大或更小的數。如下圖所示,kernel由左至右由上而下滑動會得到9組圖形。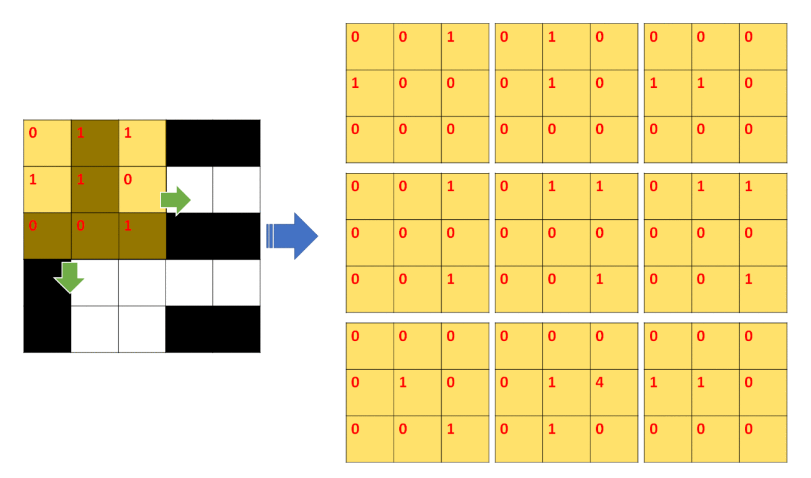
接下來,再經過ReLU函數處理,將小於0的值輸出為0,大於0則直接輸出,此結果即為所謂的feature map,此feature map上的每一點皆可視為原圖形中該區域的特徵並傳遞給下一層,CNN的卷積層就是專注在取得圖形的這些局部特徵。
kernel是逐步移動一格,因此我們稱其stride步長為一,如果我們把stride加大,那麼涵蓋的特徵會比較少,但速度較快,得出的feature map更小。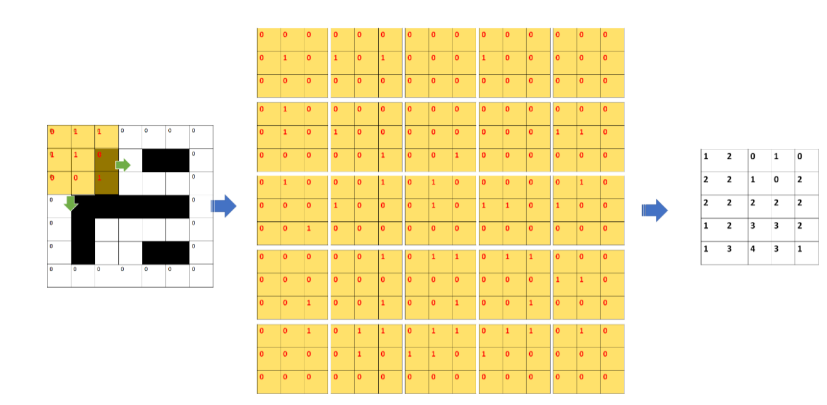
卷積層會依據指定的kernel大小及stride,取圖像各區域的特徵值再與kernel各點的權重相乘計算最後得到feature map,此map會傳給下游的池化層。所以在多個捲積層中,圖像透過kernel萃取後的特徵濃縮再傳遞給下一層,因此愈上層的捲積層會對更小的特徵起反應,而kernel的weight值會在反向傳播時逐次依loss值用ReLU activate function進行梯度修正。
參考
https://chtseng.wordpress.com/2017/09/12/%E5%88%9D%E6%8E%A2%E5%8D%B7%E7%A9%8D%E7%A5%9E%E7%B6%93%E7%B6%B2%E8%B7%AF/

